86 Introduction to Unsupervised Learning
86.1 Introduction
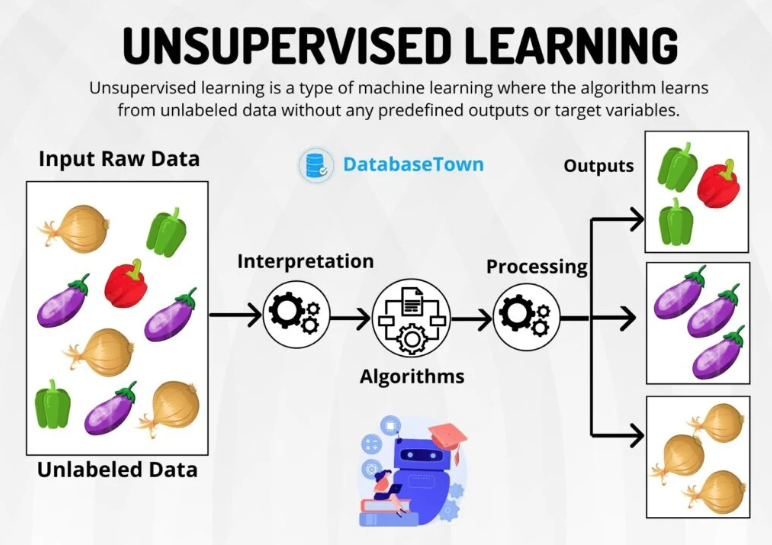
Unsupervised learning focuses on the analysis of data without predefined labels or outcomes. This is different from supervised learning, where the model is trained on labelled data.
In unsupervised learning, the algorithm is left to discover patterns, structures, or knowledge directly from the input data without prior instruction on the output.
86.2 Context
Unsupervised ML helps us understand the hidden structures within complex datasets. By learning patterns from untagged data, unsupervised methods try to model the underlying structure or distribution to reveal significant insights about the data.
Unlike supervised learning, where the goal is to predict or classify based on known output labels, unsupervised learning seeks to uncover the latent features and relationships inherent in the data itself.
This is particularly valuable in scenarios where our data doesn’t come with predefined labels, or where it’s impractical or too costly to label the data manually.
By identifying patterns and structures autonomously, unsupervised learning algorithms can provide a deeper understanding of the data, often uncovering unexpected correlations or clusters that might not be apparent through manual exploration.
86.3 Key Characteristics
No predefined labels
The key feature of unsupervised learning is its operation on data without predefined labels or target outcomes.
The algorithms must make sense of the data without guidance, categorising information based on inherent similarities and differences.
Discover intrinsic structure
Unsupervised learning algorithms try to uncover the inherent structure within the data.
They analyse the dataset to find patterns or groupings without any external input regarding how results should be structured.
This discovery process is fundamental for understanding complex datasets, where the relationships between elements are not immediately apparent.
Applications
Applications of unsupervised learning are many and varied:
In clustering, algorithms seek to group data points into clusters such that points within a cluster are more similar to each other than to points in other clusters.
‘Dimensionality reduction’ involves reducing the number of random variables under consideration, by obtaining a set of principal variables.
Techniques like Principal Component Analysis (PCA) and t-Distributed Stochastic Neighbor Embedding (t-SNE) are often used for feature extraction, data visualisation, and in preparation for further learning tasks.